Flow to Better: Offline Preference-based Reinforcement Learning via Preferred Trajectory Generation
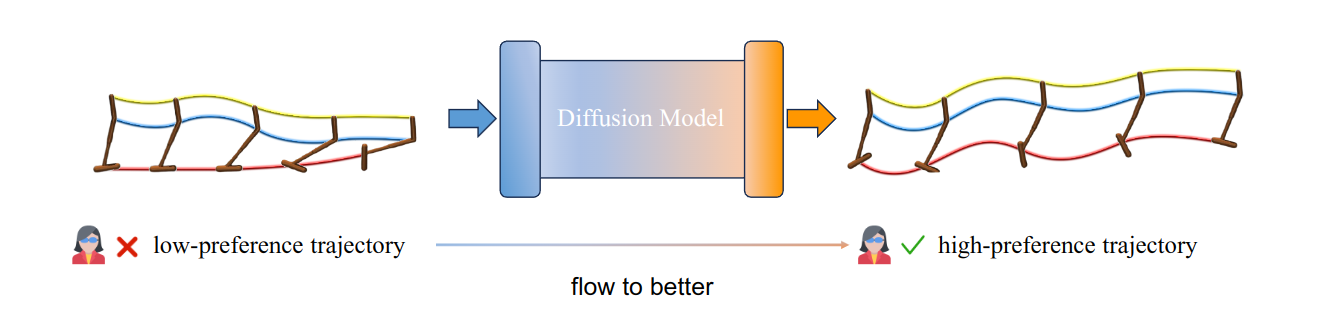
Abstract
Offline preference-based reinforcement learning (PbRL) offers an effective solution to overcome the challenges associated with designing rewards and the high costs of online interactions. Previous studies mainly focus on recovering the rewards from the preferences, followed by policy optimization with an off-the-shelf offline RL algorithm. However, given that preference labels in PbRL are inherently trajectory-based, accurately learning transition-wise rewards from such labels can be challenging, potentially leading to misguidance during subsequent offline RL training. To address this issue, we introduce our method named Flow-to-Better (FTB), which leverages the pairwise preference relationship to guide a generative model in producing preferred trajectories, avoiding Temporal Difference (TD) learning with inaccurate rewards. Conditioning on a low-preference trajectory, FTB uses a diffusion model to generate a better one, achieving high-fidelity full-horizon trajectory improvement. During diffusion training, we propose a technique called Preference Augmentation to alleviate the problem of insufficient preference data. As a result, we surprisingly find that the model-generated trajectories not only exhibit increased preference and consistency with the real transition but also introduce elements of novelty and diversity, from which we can derive a desirable policy through imitation learning. Experimental results on several benchmarks demonstrate that FTB achieves a remarkable improvement compared to state-of-the-art offline PbRL methods. Furthermore, we show that FTB can also serve as an effective data augmentation method for offline RL.
Trajectory Diffuser


Results Overview
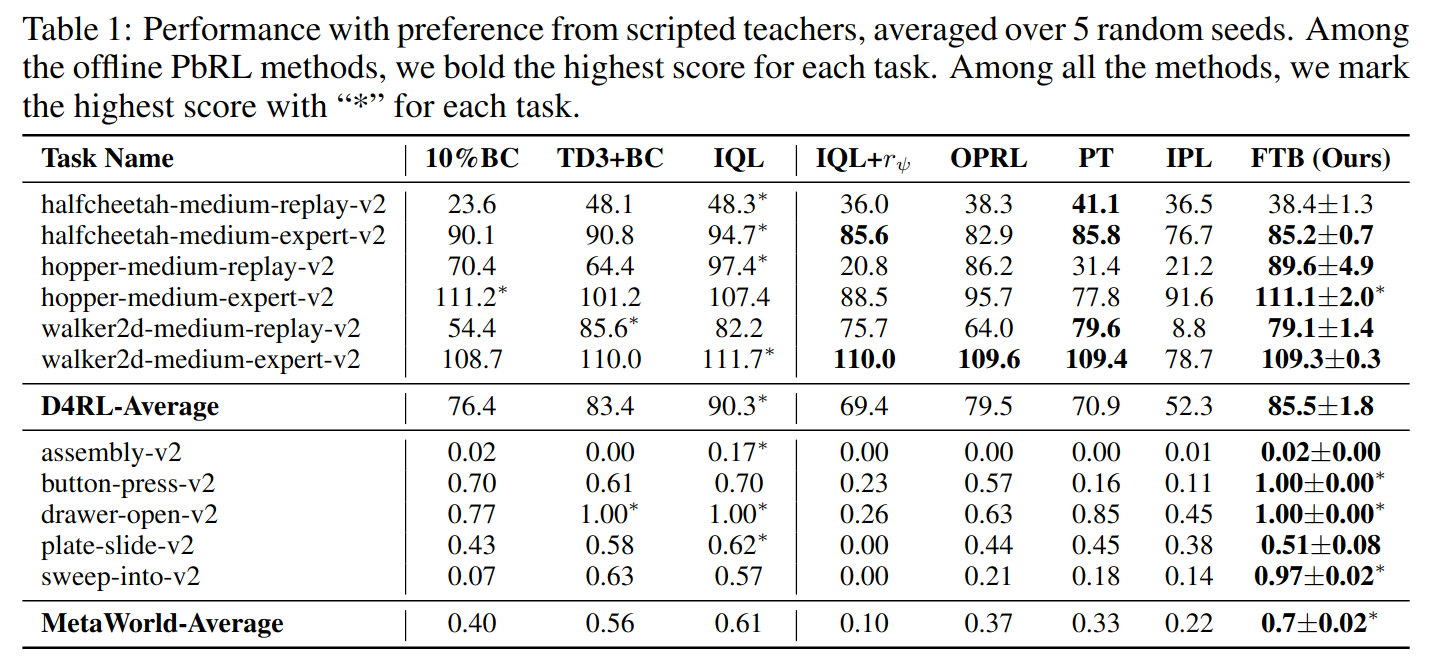
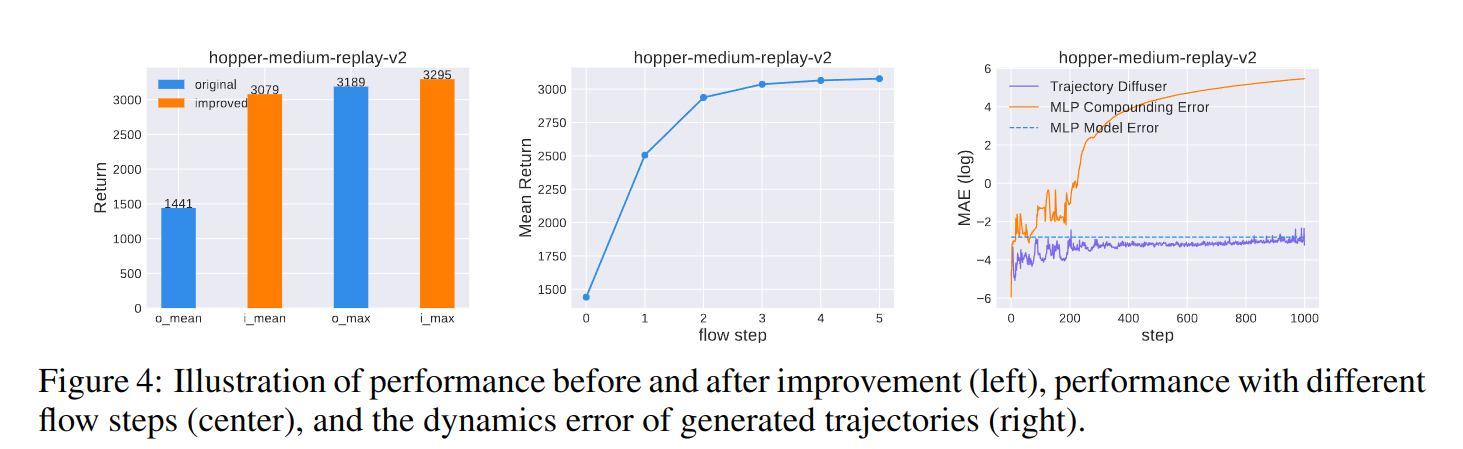
Generated Trajectories Analysis
Visualization under different flow steps

Quantitative analysis
Bibtex
@inproceedings{
zhang2024flow,
title={Flow to Better: Offline Preference-based Reinforcement Learning via Preferred Trajectory Generation},
author={Zhilong Zhang and Yihao Sun and Junyin Ye and Tian-Shuo Liu and Jiaji Zhang and Yang Yu},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=EG68RSznLT}
}